
Letter 108: What Are LLMs, and How Do They Work?
You've been using them every day. Here's what's going on under the hood.
Alright people seem to be enjoying the AI content lately so we’re gonna keep it going. That said, the market is on the up and up lately so we gotta take a look at crypto again soon and see what’s worth paying attention to.
But for today, we’re taking a foundational look at LLMs. I’ve noticed that most people who use ChatGPT or Claude every day have no idea how they actually work.
Which is fine of course. You don’t need to know how an engine works to drive a car. But I think having a basic understanding of what’s going on under the hood makes you a better user. It helps you understand why the AI is good at some things and bad at others, it helps you ask better questions, and it makes you less likely to either over-trust or under-trust the outputs.
This turned into quite a long piece, here’s what we’re going to cover:
What is an LLM?
How does an LLM “learn”?
Wait, so it’s autocomplete?
What are tokens?
What about parameters?
How do LLMs actually generate their responses?
And what do these models really “know”?
What is training vs fine tuning?
Why are some models better than others?
Model sizes: why some run on your laptop, and others need data centres
How does knowing all of this help you?
If you’re interested in leveling up your AI learning journey even more, then check out the new company I have launched alongside a couple of friends: The Stoa of AI.
We create video courses and have weekly live workshops and calls that show you practical ways to implement AI into your daily workflows.
We’re in early access mode with discounted pricing, check us out here: https://www.skool.com/thestoaofai
What is an LLM?
LLM stands for Large Language Model. That’s what ChatGPT, Claude, Gemini, and all the other AI chatbots are built on.
Language. These models work with language. Text in, text out. You type words, they generate words back. (Yes, they do images and audio and code now too, but at their core, they are language machines, and the word “language” can be used for whatever input/output is being generated by these LLMs).
Model. In AI, a model is a program that has been trained on data to recognize patterns. If you showed someone who had never seen a cat, a million photos of different breeds of cats, eventually they’d get great at telling the difference between them. An LLM is the same concept.
Large. These models are LARGE. They are trained on enormous amounts of data. We’re talking about a significant chunk of the entire internet. Books, articles, Wikipedia, forums, code repositories, academic papers. Billions, maybe trillions, of words.
Put it together and you get: a program that has read a huge portion of human text and learned the patterns of language from it.

How does an LLM “learn”?
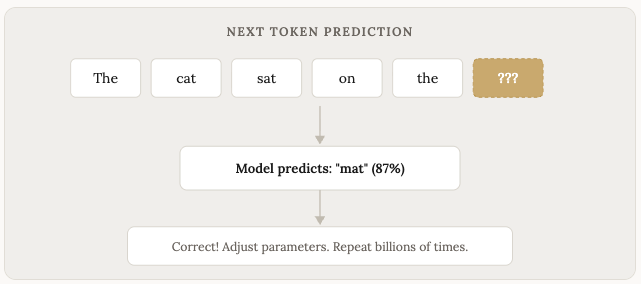
The core learning of “training” process is surprisingly simple in concept. You take a sentence, hide the last word, and ask the model to predict what comes next.
“The cat sat on the ___”
The model guesses. If it gets it wrong, you adjust the model slightly so it does better next time. Then you do this billions and billions of times, with billions and billions of sentences.
Over time, the model gets good at predicting the next word. And then the next word after that. And the next. Until it produces entire paragraphs and pages that sound like a human wrote them.
This is a simplified version of the process (the technical term is “next token prediction”), but it captures the core idea. LLMs are, at their foundation, prediction machines. They predict what text should come next based on everything they’ve seen before.
Wait, so it’s autocomplete?
Kind of. This is a comparison that gets thrown around a lot, and it’s partially accurate.
Your phone’s autocomplete predicts the next word based on simple patterns. LLMs do the same thing, but with astronomically more data, vastly more computing power, and a much deeper understanding of context.
The difference in scale creates a difference in kind. Your phone’s autocomplete might suggest “the” after “in.” An LLM will write you a coherent essay about quantum physics, maintain a consistent argument across 2,000 words, and format it properly. Both are predicting the next word. One is doing it with such depth and sophistication that it produces something that looks and feels like understanding.
Whether or not it is understanding is one of the great debates in AI right now. I don’t think we need to settle it here. What matters for practical purposes is that the output is useful, and often impressively so.

What are tokens?
Tokens are the units that LLMs work with, and they’re also sorta considered the currency of LLMs. When you use a frontier model from Anthropic or OpenAI, you’ll generally be paying per token used.
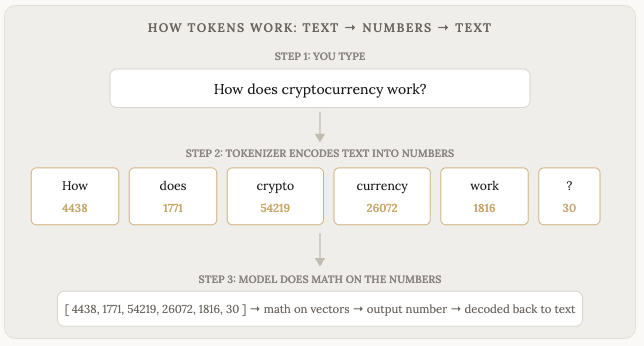
Here’s something most people don’t realize: the model never actually sees your words. It only sees numbers.
When you type a message, the first thing that happens is your text gets encoded into tokens, where each token is assigned a number. The word “hello” might become token 15339. The word “the” might be token 1820. The word “cryptocurrency” might get split into two tokens: “crypto” (54219) and “currency” (26072).
These numbers are what the model works with. Every single computation that happens inside the model, all the pattern matching, all the predictions, happens as math on numbers. The model processes these numbers through its neural network, and outputs... more numbers. Those output numbers then get decoded back into words that you read on your screen.
Encode → Math → Decode. That’s the whole loop.
The process of converting text into numbers is called encoding. The process of converting the output numbers back into text is called decoding. You never see the numbers, and the model never sees the words. There’s a translation layer (called a tokenizer) sitting between you and the model, encoding and decoding back and forth.
So what happens during the “math” part? Each token number gets converted into a vector, which is a long list of numbers (hundreds or thousands of them) that represents the meaning and context of that token. The word “bank” in “river bank” gets a different vector than “bank” in “bank account” because the surrounding tokens influence the representation.
The model then runs these vectors through layers of calculations, adjusting and combining them, comparing every token to every other token to figure out relationships and context (this is the “attention” mechanism you might have heard about). After dozens of these layers, the final output is a probability distribution over every possible next token. The model picks one, decodes it back to text, and voila! you see a word appear on your screen.
This is also why LLMs are sometimes weird about things like counting letters in a word or doing arithmetic. The model doesn’t see the word “strawberry” as s-t-r-a-w-b-e-r-r-y. It sees it as one or two token numbers. It has no concept of individual letters because those letters got encoded away before the model ever touched them.
A token is roughly 3/4 of a word, or about 4 characters. Common short words like “the” or “and” are one token. Longer or less common words get split into multiple tokens.
This matters to you because LLMs have a limit on how many tokens they process at once. This is called the context window. Think of it as the model’s working memory.
If a model has a 200,000 token context window, that’s roughly 150,000 words it is able to hold in mind at one time. Some models now go even higher. Claude Opus 4.6, Claude Sonnet 4.6, and Gemini all support 1 million token context windows. That’s about 750,000 words, or roughly 10 to 15 full novels. Llama 4 Scout from Meta supports a whopping 10 million token context. These are staggering numbers compared to where things were a few years ago.
But something to keep in mind is that larger context windows aren’t necessarily or inherently better.
As you stuff more and more tokens into the context window, the quality of the model’s responses tends to degrade. Researchers call this “context rot.” The model doesn’t attend equally to everything in its context. It tends to pay the most attention to stuff near the beginning and the end, and less attention to stuff in the middle. A 2023 research paper found that when relevant information was buried in the middle of a long context, models performed significantly worse at finding and using it.
This means that giving the model more context isn’t always better. If you dump 500,000 tokens of loosely related documents into the context window and your actual question relates to a detail somewhere in the middle, you might get a worse answer than if you had only provided the 10,000 most relevant tokens. Quality context beats quantity of context. It’s a little counterintuitive, but it’s how it works.
Just like everything AI related, the models are getting better at this too. Claude scores at the top of long-context benchmarks, and the gap between small-context and large-context performance is shrinking with each generation.

What about parameters?
This is another big number you hear about. Lots of models tout billions or hundreds of billions of parameters; some have trillions. But what even are parameters?
Parameters are the model’s internal settings. Think of them as tiny dials, and during training, each of these dials gets adjusted slightly every time the model makes a prediction and gets feedback on whether it was right or wrong.
To put it more concretely, parameters are the numbers that determine how the vectors mentioned in the previous section get transformed as they pass through the model. They control things like: how much attention should this word pay to that word? How should this concept relate to that concept? What patterns are important and what patterns are noise?
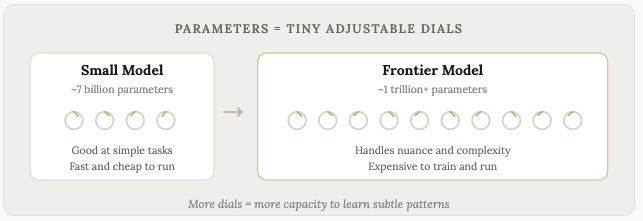
Every connection between neurons in the neural network has a parameter (a weight) that controls the strength of that connection. A 7 billion parameter model has 7 billion of these connections. A trillion parameter model has a trillion. Each one was tuned, bit by bit, over trillions of training examples.
A model with more parameters has more dials to tune, which means it has the capacity to learn more subtle and complex patterns. A small model might learn that “the cat sat on the mat” is a common pattern. A large model learns that too, but it also learns that the sentiment of a paragraph shifts when you use the word “however,” or that a question phrased politely tends to expect a different kind of answer than a blunt one. The larger the model, the more of these subtle relationships it picks up.
More parameters generally means a smarter model, though it’s not the only factor. Training data quality, architecture decisions, and fine-tuning all matter too, and we’ll talk about that in a bit. But all else being equal, more parameters = more capacity to learn complexity.
The tradeoff is resources. Every parameter takes up memory. Running a model means loading all of those parameters into RAM (or GPU memory) and doing math on them for every single token generated. That’s why bigger models need more expensive hardware, cost more to run, and generate tokens slower.
You don’t really need to remember the exact numbers or know how things work precisely for this stuff.
The takeaway is: parameters = the model’s capacity to learn complexity.
How do LLMs actually generate their responses?
When you type a message to Claude or ChatGPT, here’s roughly what happens:
Your message gets converted into tokens (numbers)
The model processes those numbers through its neural network (the billions of parameters)
It predicts the most likely next token (number)
That number gets added to the sequence, and the model predicts the next one
Repeat, one token at a time, until the response is complete
This is why you see the text appear word by word when the AI is responding. It’s generating the response in real time, one piece at a time. It doesn’t write the whole answer and then reveal it. It is figuring it out as it goes.
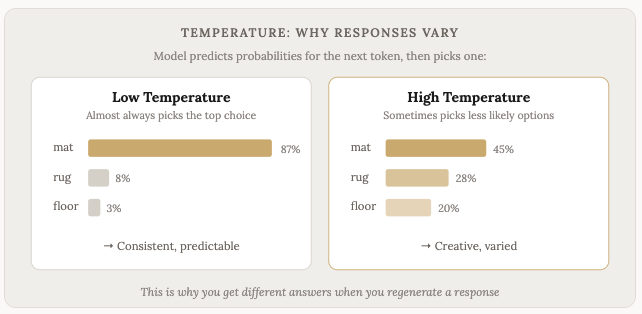
This is also why the same prompt sometimes gives you different answers. There’s a degree of randomness (called “temperature”) built into the selection process. The model doesn’t always pick the single most likely next token. Sometimes it picks the second or third most likely option, which sends the response in a slightly different direction.
On most models you can also adjust this setting and request the model to use more of the less-standard responses. This is helpful if you’re doing something like creative writing or anything really where you need outside-of-the-box thinking. For anything that requires facts and exactness, low temperature models tend to perform better.
And what do these models really “know”?
LLMs don’t have a database of facts that they look up. They don’t search through a filing cabinet when you ask them a question. Instead, the knowledge is embedded in the patterns of their parameters. The model learned that certain facts tend to appear in certain contexts, and it reproduces them when the context calls for it.
This is why LLMs sometimes make things up. The AI community calls these “hallucinations.” The model isn’t lying. It’s generating text that seems like the most probable continuation of the conversation, and sometimes the most probable-sounding thing isn’t true. It’s predicting, not recalling.
This is one of the most important things to understand about LLMs. They are optimized to produce text that sounds right. Not text that is right. These two things overlap a lot of the time, but not always.
Rule of thumb: the more obscure or specific the fact, the more likely the model is to get it wrong or make it up. If you ask about well-documented topics that appeared frequently in the training data, the model is pretty reliable. If you ask about niche topics, recent events, or specific numbers, then verify the output.

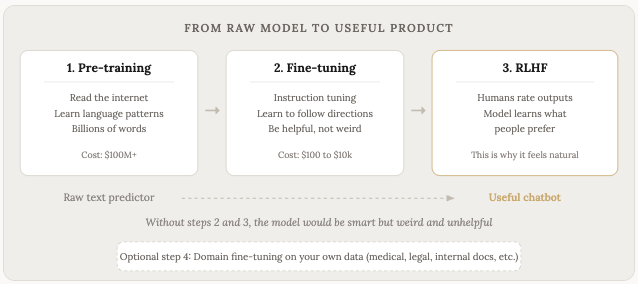
What is training vs. fine-tuning?
Training is the initial process where the model reads all that text and learns the patterns. This is expensive and time consuming. Training a frontier model costs hundreds of millions of dollars in compute alone (this phase is sometimes called pre-training because it happens before any further refinement).
The result of pre-training is called a base model. Base models are smart, and they know a lot about language, but they’re weird to talk to. If you ask a base model a question, it might continue your text as if it’s writing a Wikipedia article, or generate random forum posts, or complete your sentence in a direction you didn’t expect. It doesn’t know it’s supposed to be helpful. It’s a text prediction machine, but not a conversational assistant like we’re used to engaging with like with chatGPT etc.
Fine tuning is what turns a base model into something useful. It’s a second round of training, done on a much smaller and more carefully curated dataset. This is where the model learns to follow instructions, answer questions, have conversations, and generally behave the way you’d expect a chatbot to behave.
There are a few different types of fine-tuning worth knowing about:
Instruction tuning is where you train the model on thousands of examples of “here’s an instruction, here’s the correct response.” This teaches the model to follow directions instead of completing text randomly.
RLHF (Reinforcement Learning from Human Feedback) is where humans rate the model’s outputs, and the model learns to produce responses that people prefer. This is a big part of why modern chatbots feel natural to talk to. The model learns things like “be concise when the question is simple” and “acknowledge uncertainty when you’re not sure” from human preferences.
Domain-specific fine-tuning is where you take an existing model and train it further on data from a specific field. A hospital might fine-tune a model on medical records so it becomes better at clinical language. A law firm might fine-tune on case law. A company might fine-tune on their internal documentation so the model understands their products and processes. This is where things get interesting for businesses.
The cost difference between pre-training and fine-tuning is enormous. Pre-training GPT-5 or Claude from scratch costs hundreds of millions. Fine-tuning an open source model on your own data costs anywhere from a few dollars to a few thousand, depending on the size of the model and how much data you’re using.
This is one of the reasons open source models matter so much. You take a free base model like Llama or Mistral, fine-tune it on your specific data, and you end up with a custom model that understands your domain, runs on your own hardware, and costs nothing per query. That’s a big deal for businesses that process a lot of data and don’t want to send it to a third party API.
Why are some models better than others?
We covered this a bit already, but just to highlight and expand upon a few factors in a bit more detail:
Training data quality. More data isn’t always better. Cleaner, higher-quality data leads to better models. If you train on a lot of garbage, the model produces garbage.
Model architecture. How the model is structured internally matters. The Transformer architecture (introduced in a 2017 paper by Google researchers called “Attention Is All You Need”) is the foundation for all modern LLMs. There are meaningful differences in how each company builds on top of that foundation.
Scale. More parameters and more training compute generally lead to better performance, up to a point. There are diminishing returns, and smaller models trained on better data sometimes beat larger models trained on worse data.
Fine-tuning and alignment. How the model is refined after initial training makes a huge difference in how useful it feels to talk to.
Context window size. How much the model keeps in mind during a conversation affects its ability to handle complex, multi-part tasks.

Model sizes: why some run on your laptop and others need a data center
As we’ve established, not all models are the same size. Parameter count varies hugely, and that directly determines what hardware you need to run them.
A rough rule of thumb: each billion parameters needs about 0.5 to 1 GB of RAM (depending on the precision/quantization). A 7 billion parameter model needs around 4-8 GB of RAM. A 70 billion parameter model needs around 40 GB. Frontier models from OpenAI, Anthropic, and Google have hundreds of billions to over a trillion parameters, and they require massive clusters of specialized GPUs that cost millions of dollars.
This is why some models are available to run locally on your own computer, and others are only accessible through cloud APIs. You pay per token to use GPT-5 or Claude because the infrastructure required to run them is enormous. But you download and run Llama 8B or Mistral 7B on a decent laptop for free.
There’s also a technique called Mixture of Experts (MoE) where a model has a huge total parameter count but only activates a fraction of them for each token. DeepSeek V3 has 671 billion total parameters but only uses 37 billion per token. GLM-5.1 has 744 billion total but only 40 billion active. This lets big models run on smaller hardware than you’d expect.
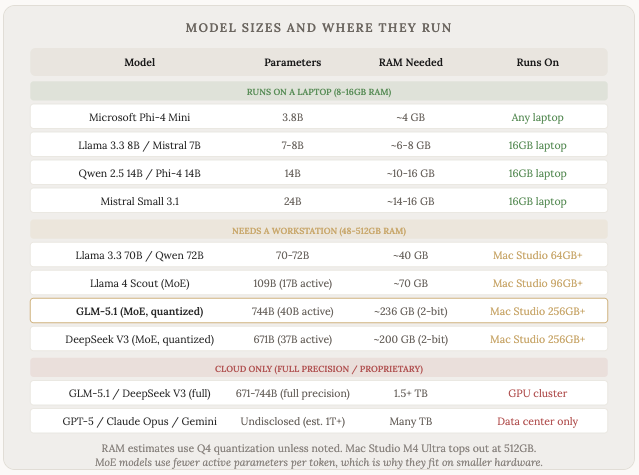
The quality gap between the smallest and largest models is real, but it’s also shrinking. A well-chosen 14B parameter model running on your laptop today can do a decent job of everyday and simple tasks even compared to the frontier models (although it might be slower).
The gap is most noticeable in complex multi-step reasoning, long creative writing, and tasks that require a lot of world knowledge. For everyday stuff like drafting emails, summarizing documents, or answering questions, the local models are surprisingly good.
And of course not all local models are created equal. GLM5.1 is a surprisingly good model that can run on a mac studio, which, while still very expensive ($5-10k+), pales in comparison to the millions of dollars the massive data centres cost to build.
How does knowing all of this help you?
I mean, hopefully you just find this stuff super interesting like I do! There’s value in knowledge, and in knowing how things work, even if you don’t really need to know in order to use them.
Some of that value comes from some changes you might make when using these tools.
When you know that the model is predicting the next token based on patterns, you understand why giving it more context leads to better outputs. You understand why being specific in your prompts matters. You understand why it sometimes confidently says things that are wrong.
When you know about context windows, you understand why long conversations sometimes go off the rails.
When you know about temperature and randomness, you understand why regenerating a response sometimes gives you something better (or worse). It’s a different path through the probability space. And knowing that you can adjust the temperature settings depending on the task can allow you to harness these tools in a way that is specific to your needs.
You also start to appreciate what these tools are and aren’t. They’re not search engines (though they now have search built in). They’re not databases. They’re not oracles. They’re pattern-matching machines of extraordinary sophistication, trained on a large percentage of humanity’s written knowledge (and then further trained / fine tuned with additional and curated human feedback).
That makes them useful.
It also makes them fallible in specific, predictable ways.
Knowing all of this should make you a better user, and give you more confidence in your prompting future.
Disclaimer: The content covered in this newsletter is not to be considered as investment advice. I’m not a financial adviser. These are only my own opinions and ideas. You should always consult with a professional/licensed financial adviser before trading or investing in any cryptocurrency related product. Some of the links shared may be referral links.
Thank you for sharing this, I learned a lot.
Thanks for the article!